【比赛复盘】云上开发,高效智能–阿里云ECS Cloudbuild开发者大赛性能挑战赛道
前言
快暑假的时候,在阿里天池上面闲逛。诶,性能优化挑战赛?点进去看看,初略的读了一下赛题,要实现一个聊天室服务,部署在ECS服务器上面,然后对它进行一下手段的性能优化,感觉还挺合适的(ps: 当时因为写了一个秒杀系统并压测优化过、也看过一些性能调优的书,感觉自己很nb,后面才知道自己还是太嫩了🤣),顿时就报名了。
因为第一次参加这种比赛,所以给自己定的是前50就ok了。然后一个月的初赛,快结束的那一周排名十多名,感觉自己还是很厉害的,但是就一周的时间,看着自己排名直接跌出前 20,到了 23。才意识到自己高兴太早了。
接下来是一个月的复赛时间,这回是要实现一个集群了。中途遇到了老多问题,找了好多官网文档(Vertx、Hazelcast、Ignite、LevelDB),也学到了不少,但还是感觉差点火候😅。每天早上七点多起床一直调试到晚上十点左右,官方人员都被烦的不要不要的了😂(希望不要厌烦)。还是太菜了哈哈哈。
不多说了,先上排名。

赛题
背景:基于公共云构建产品、系统和应用已经是当前最热门的技术趋势了。赛题探讨Web Service在云上部署的性能优化,希望参赛者通过代码撰写、操作系统与数据库选型、各种参数调优等手段,优化云端Web服务的性能和保障服务的高可用。
描述:根据给定的API完成:用户注册、用户登录、创建房间、查看房间、用户进入、退出实时聊天房间、用户发言和实时收取其他人的消息。注:聊天室、消息和用户,三个数据必须持久化;在线人数无须持久化。需要保证程序返回时宕机,数据还存在,允许很少的丢失。三台服务器。
机器规格:4 核 8 G
评分:能测试的综合得分= n ∗ 10 + 50 ∗ (qps / 10000) ∗ k + 50 ∗ (1 / time_deplay) ∗ m。
优化点
线程模型
一开始系统的架构采用的是Springboot + redis(用了MySQL,直接没出分😅)。写完程序后提交,纳尼?居然才拿到了简单的API正常分(190)?立马打开Jprofiler开始监控,发现压测的时候线程数只有几十个并且线程大多都处于等待状态,而且CPU利用率很低。ok,提高tomcat的线程数(因为Springboot是内嵌tomcat的,而且一个请求会有一个线程去处理),不断的调整,最后找到最优的线程数。鸡冻!立马打开提交界面开始提交,过了几分钟,QPS得分提高 5 分???怎么才 5 分?我测了这么久!算了算了,提高了就好。
但是接下来一段时间,陷入艰难的时刻了,不断的修改、提交,但是分数老是上不去。不行不行,不能就这样下去,大概在网上找了好几天,期间都差点想去学C++的seastar,后面在techempower网站上找到了性能较高的web容器Vertx,终于看见了曙光。花了 3 ~ 5 天去熟悉Vertx一个个的demo,后面根据需要然后不断的找文档、加功能,一个webserver弄好了!(不得不说,Vertx的文档是我见过最容易懂的,学的最快的)先点个提交看看,300+!芜湖。
同步模型
像传统的Springboot就是同步模型(其实是tomcat),收到一个请求后,就用一个线程去处理,只能处理一个,其他线程就可能会被阻塞,这样就会大大的降低系统的吞吐量。虽然tomcat后面也支持NIO以及AIO,但是在比赛初期的时候使用了但是效果不太明显,就舍弃了。
多路复用模型
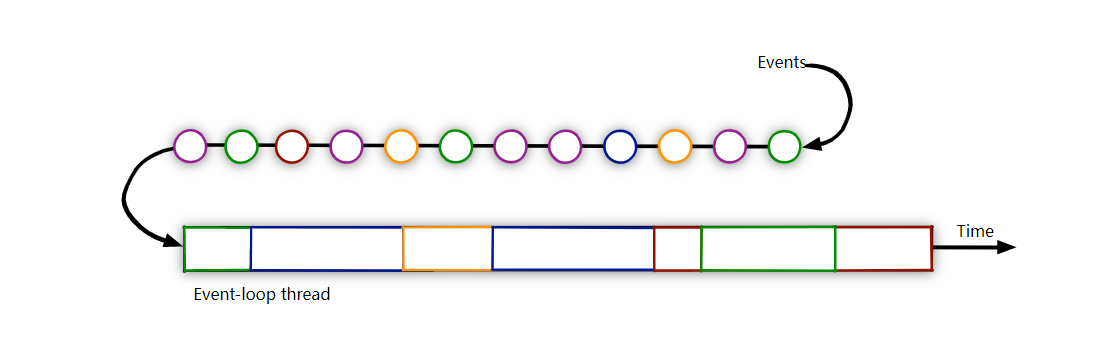
像我们知道的Linux中的select、poll和epoll,又或者是Redis中的,都是使用的IO多路复用。Vertx正是使用了这种模型,它通过一个Event Loop组不断的循环,当有Event到达时,它会调用相应的handle去处理。这就使得它相比于同步模型有着天然的性能优势,能够处理更多的请求。注意:不要在Event Loop运行时间较长的代码,Vertx有专门用于处理耗时长的代码线程(Worker Verticle)。
线程数
我们前面说到Vertx是通过一个Event Loop组来不断的循环以及Worker Verticle来处理阻塞代码,但是它们的线程数量应该如何去设置呢?我的思路:Event Loop因为是不断循环的,线程数应和CPU核数差不多。而Worker Verticle处理阻塞代码,可以尽可能的多。最终经过不断的benchmark,调整线程数,最终提高的大概 50 多分。
1 | |
数据写入
这是另外一个大头。因为以前接触存储这方面比较少,当时认知里面Redis最快,在使用的时候一直开启aof的AOF_FSYNC_ALWAYS,因为赛题要求系统返回就意味着数据罗盘。后面公布可以允许少量的数据丢失后,开启了AOF_FSYNC_EVERYSEC,分数提高了 100 分左右。然后在网上参考一些写性能快的中间件(可能是我没搜引擎之类的,居然没看见LevelDB),后面不知道是哪个博客上面给的测试报告,说MongoDB的写性能优于Redis,然后花了好几天的时间去弄MongoDB和测试,但是在 4 核 8 G的情况下,内存占用太多,并且性能也没Redis好。然后参考了MongoDB的实现,异步定时刷盘。后面就在想自己弄个存储的,直接写,不调中间件了,整个方案是写在内存中然后到达某一阈值 / 时限后异步刷盘,但是测试出来效果都不理想,就给放弃了。后面就是乱找了,像Cassandra、ScyllaDB这些(当时居然没想到看底层是如何实现的了)。
后面初赛完才了解到LevelDB以及LSM树。详情见:LSM论文
集群(通信 / 数据传输)
这其实都还挺好弄的,主要是一般以上的节点 ack true 后 response。当时考虑的方案有
- 通过分布式缓存实现。像Redis集群,又或者嵌入在程序里面的Hazelcast、Ignite。
- 自己实现
但是当时因为在其他方案上面浪费了很多时间,所以就选择了成熟的实现较快的方案:Ignite。其他方面的原因就是当时想着嵌入在应用程序里面比像Redis额外开一个进程资源消耗低以及网络IO少。但是为什么不选择Hazelcast呢?因为这个东西持久化缓存的话需要 money !!!
像这种简单、需求不多、追求性能的场景感觉还是自己实现并且在一个程序里面好点。
至于数据传输的格式,protobuf就挺不错的,兼容性和性能都挺好。其他的像Json、Xml用的比较多。
比赛完后实现了一个通过Java实现Raft算法,具体详情移步到该文章。
数据分区
刚拿到复赛赛题的时候,一开始考虑的是集群每个节点都保存一份完整的数据(ps: 当时想着快速响应,当本地内存中存有数据时,这样最快),后面测试过程中发现查询的效率是挺快的了,但是当集群面临写多的场景下,就出现了很多问题。比如说消息顺序乱(考虑的是时间戳来解决)、集群之间数据同步太慢(主要原因)。后面还是将数据进行了分区存放,集群中每个节点都会存储一块区域的数据,当本地分区没有该数据时,就会去其他分区查询,并可以按需要将查询到的数据缓存到本地,这样做后性能提高了不少。
但是随之而来的问题就是当存储某一分区的节点宕机之后,其他节点如何访问该分区的数据?
后面在Ignite官网查看到了数据再平衡机制。就是会有个中心的节点会管理分区,并将分区分配给集群中的节点,当某一节点宕机后,中心节点就会将宕机后的分区数据流转到其他两个节点上面,这样就解决的数据丢失问题。(因为评测环境不会出现三台服务器都宕机的场景,所以不管如何宕机数据都不会丢失,前提是宕机后的节点重启会先进行数据同步)
Linux可打开的文件数
这东西感觉还挺常用的哈,具体来说就是连接数的大小,因为Linux都是以fd文件描述符来弄的嘛,所以设置Linux中可以打开的最大文件数可以应对一些connection refuse的场景。具体配置:
1 | |
注意:hard nofile 一定要比 fs.nr_open 要小,否则可能会导致用户无法登录
总结
- 一个好的架构 / 设计(这会帮你省下很多时间)
- 技术的广度与深度(你可以快速的找到你所需要的技术)
- 学习能力(能够快速熟练的上手某个新的技术)
- 心态(放轻松)
加油!!!
最后
【比赛复盘】云上开发,高效智能–阿里云ECS Cloudbuild开发者大赛性能挑战赛道
http://zhaommmmomo.cn/2021/11/07/【比赛复盘】云上开发,高效智能–阿里云ECS Cloudbuild开发者大赛性能挑战赛道/