重点
randLevel算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#define ZSKIPLIST_MAXLEVEL 64
#define ZSKIPLIST_P 0.25
private int randLevel() {
int level = 1;
while ((random() & 0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
|
跳表
论文地址
简介
SkipList是用于有序元素序列快速搜索查找的一个数据结构,跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。它在性能上和红黑树,AVL树不相上下,但是跳表的原理非常简单,实现也比红黑树简单很多。
下图是一个简单的skiplist
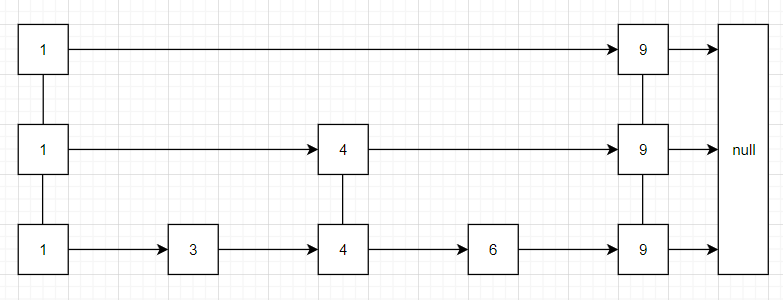
原理
说白了就是一个有序链表加上索引,以空间换时间。
结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class SkipList {
private Node header;
private Node tail;
private long length;
private int maxLevel;
private int level;
public Class Node {
private List<Node> levels;
private Entry entry;
private float score;
}
}
|
Get
如果我们需要查询6这个位置的数据
skiplist会进行如下查询:
- 先从节点1的最高层进行与下一个节点9进行比较,小于节点9,层数降低。
- 再将节点1与下一个节点4进行比较,大于节点4,指针指向节点4。
- 然后将节点4与节点9进行比较,小于节点9层数降低。
- 将节点4与节点6比较,这时候找到了需要查询的节点,进行返回。
(如果层数的最低层并且没找到就返回null)
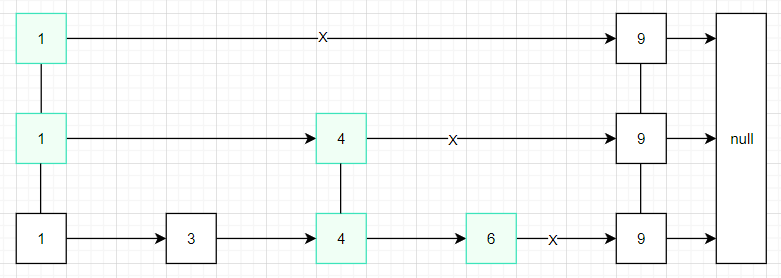
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public byte[] get(byte[] key) {
float score = calcScore(key);
List<Node> levels = header.levels;
for (int i = level - 1; i >= 0; i--) {
Node next = levels.get(i);
while (next != null) {
int flag = compare(score, key, next);
if (flag == 0) {
return next.getEntry().value;
} else if (flag == -1){
break;
}
levels = next.levels;
next = levels.get(i);
}
}
return null;
}
|
Add
与查找的方法类似,但是需要记录查找所经过的节点。
如果我们需要添加节点5
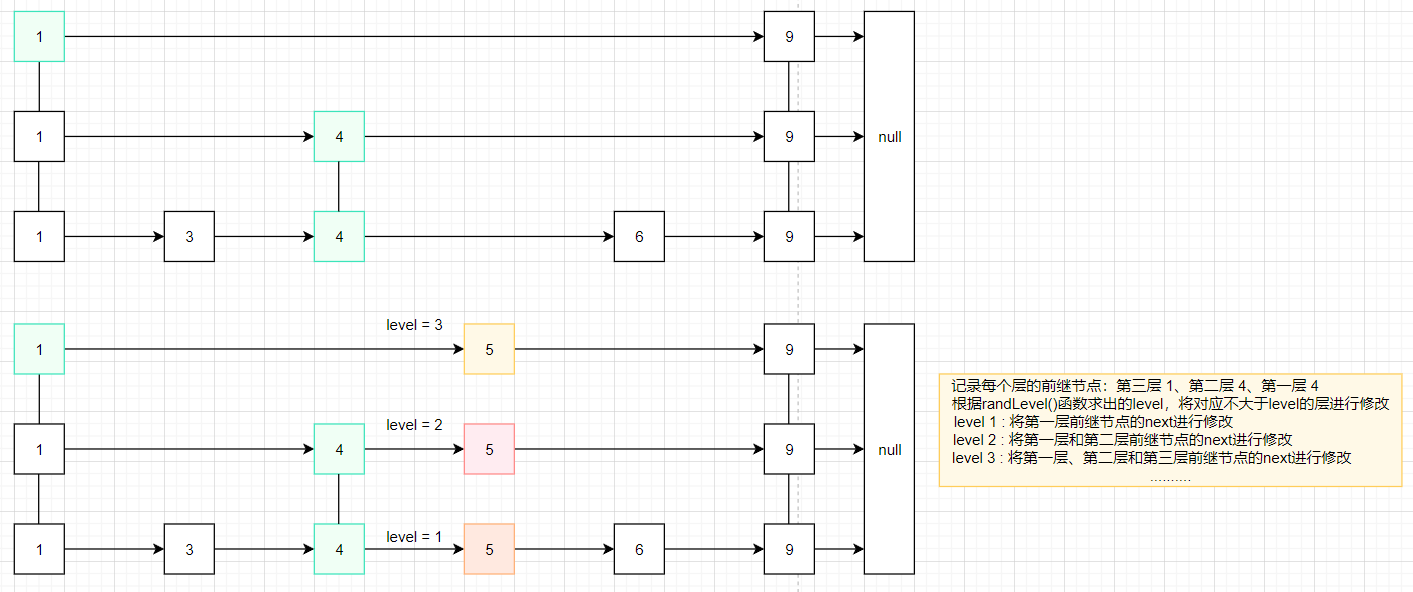
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public boolean add(Entry entry) {
float score = calcScore(entry.key);
Node[] preNode = new Node[level];
Node p = header;
List<Node> levels = p.levels;
Node next;
for (int i = level - 1; i >= 0; i--) {
next = levels.get(i);
while (next != null) {
int flag = compare(score, entry.key, next);
if (flag == -1) {
break;
} else if (flag == 0) {
size += entry.size() - next.entry.size();
next.entry = entry;
return true;
}
p = next;
levels = p.levels;
next = levels.get(i);
}
preNode[i] = p;
}
Node newNode = new Node(entry, score);
int cLevel = randLevel();
int minLevel = Math.min(cLevel, level);
for (int i = 0; i < minLevel; i++) {
Node swap = preNode[i].levels.get(i);
preNode[i].levels.set(i, newNode);
newNode.addLevel(swap);
}
while (cLevel > level) {
header.levels.add(newNode);
newNode.addLevel(null);
level++;
}
length++;
size += entry.size();
return true;
}
|